Multi-modal Representation Learning for Product Matching in E-Commerce
This is the group project of CS7643 Deep Learniing from Georgia Tech. (Full article is available here)
Probelm Definition and Motivation
- Product matching is the key to success in E-Commerce industry, because end-users want to compare products with same categories and compare vendors and theirs prices.
- However, the task cannot be solved using traditional supervised learning methods. This is because the problem can be categorized as Zero-shot learninig, in which the model observes novel classes which haven’t been provided to the model during training time.
- One big challenge is that even for similar products, the text and image description could be completely different.
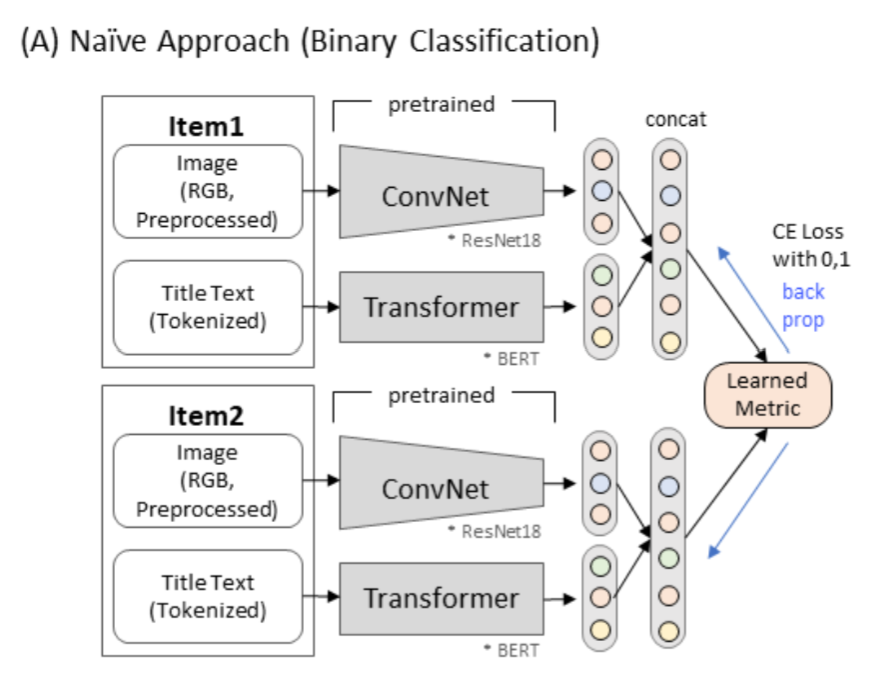
Naive Approach: Reduction to Classification Problem
- One easy approach is to have vector representation of $X_1$ and $X_2$ where their label can be formed as ${0, 1}$, which is known as
contrastive loss. In this scheme, label 1 indicates two product postings are matching. In this baseline model, we concatenate image and text embedding from ResNet and BERT and measured L1 distance, and eventually it is fed to Fully-Connected layer. - However, when there is $N$ number of product postings, it is required to build $O(N^2)$ pairs. In usual E-Commerce setting, the number $N$ can easily reach the number of millons, making the whole paired set impossible.
- One way to limit the number of training item could be limiting the negative pairs; However, during the inference time, the model would see much more negative example so we can expect that the model tends to work in more optimistic way.
- On the other hand, we can select hardest negative examples while it requires careful engineering and domain expertise.
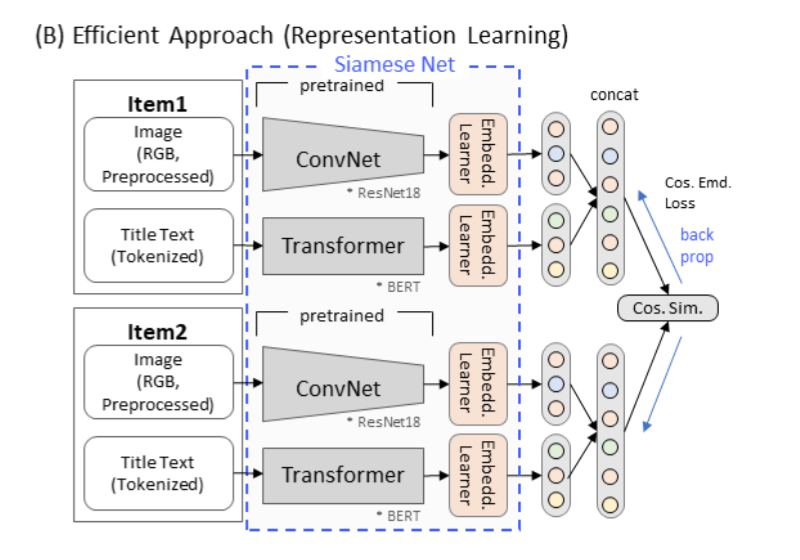
Efficient Approach: Representation Learning
- The idea is similar to the above approach (as binary classification is done as surrogate task). To be specific, we don’t train the metric itself but train intermediate vector representation, precisely embedding learner in the above figure
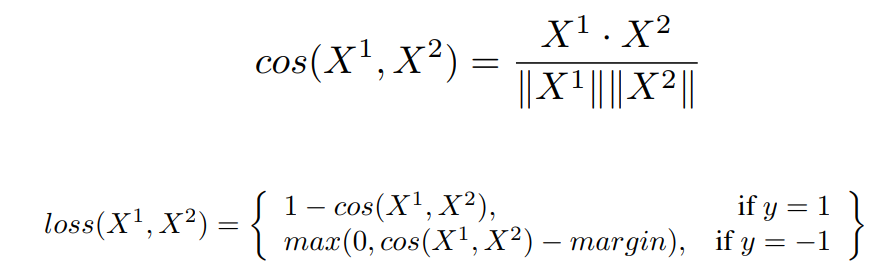
- In order to train the model’s representation power, we used Cosine Similarity metric. The intuition is, we want to reduce $\theta$ between intra-class products rather than L1 distance.
- After the training, we only have to calculate vector representation (embedding) of product posting once. Given the product embeddings, we used k-NN method the infer whether the queried product belongs to a certain group or not.
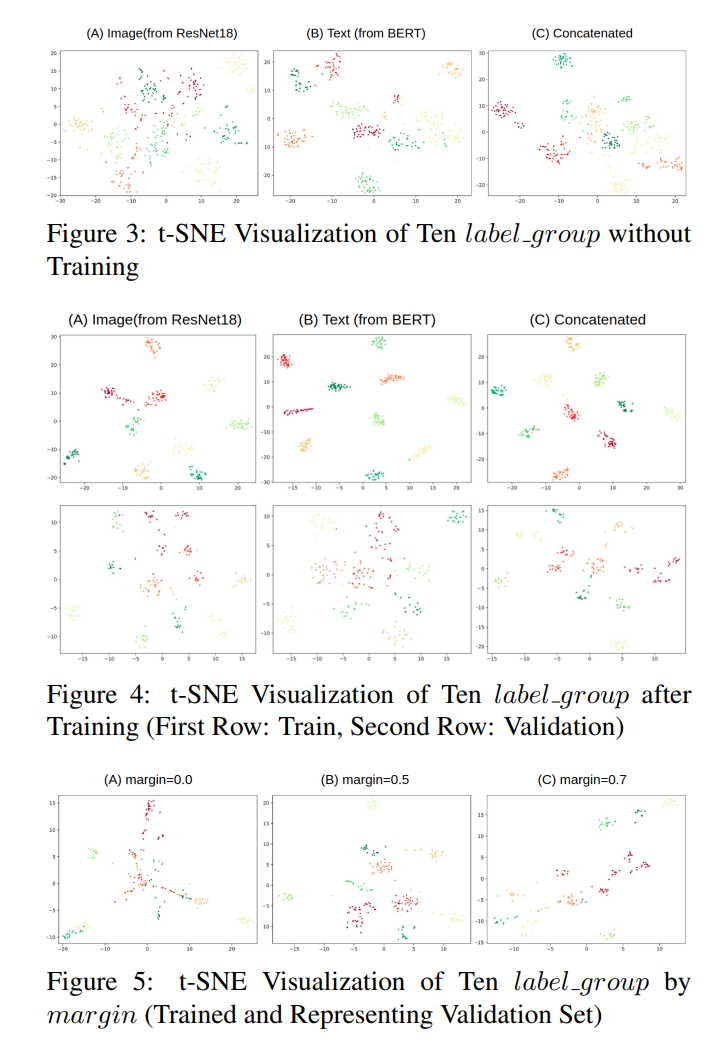
Results and Takeaways
- One issue occured during training was, concatenation of image and text resulted improper training. This improper training happens when image and text embedding don’t agree to each other. When the model incorrectly predicted a pair, backward gradient of loss penalized one of embedding learner even though the learner produced the correct embedding. In the future work, it could be beneficial to let loss gradient flow to only a problematic model.
- Also, pretrained ResNet and BERT model does a quite a good job even without training, providing evidence that pre-trained model s common sense knowledge worked.